
model Bench AI
No-code platform for side-by-side evaluation and comparison of 180+ language models.

Visão geral
Funcionalidades principais
- Multi-model prompt testing
- Side-by-side response comparison
- Library of 180+ supported LLMs
- No-code evaluation workflows
- Team collaboration on prompts
- Performance and output benchmarking
Prós e contras
Prós
- Compare 180+ models in one place
- No coding required to run evaluations
- Speeds up model selection decisions
- Side-by-side output comparison
- Collaboration-friendly workflow
Contras
- Limited value for single-model users
- Costs can grow with heavy multi-model testing
- Less flexible than custom eval pipelines
- Quality depends on prompt design
Avaliações
Média de 5 avaliações.
Entra para deixar uma avaliação.
Omar Haddad
Compared a few options
Evaluated this against two competitors. Where it wins: multi-model prompt testing and side-by-side output comparison. Where it lags: limited value for single-model users. On balance the feature set — especially performance and output benchmarking — justifies the 5 stars for our use case.
Diego Fernández
Use it every day
Honestly didn't expect to like it this much. Library of 180+ supported LLMs is exactly what I needed, and speeds up model selection decisions. I do wish limited value for single-model users, but I reach for it almost every day now and it just clicks.
Daniel Schmidt
Use it every day
Honestly didn't expect to like it this much. Side-by-side response comparison is exactly what I needed, and side-by-side output comparison. but I reach for it almost every day now and it just clicks.
Hiroshi Tanaka
Does the job
Pretty happy overall. Library of 180+ supported LLMs just works and collaboration-friendly workflow. Less flexible than custom eval pipelines can be annoying, but no dealbreakers — I'd recommend it to a friend without hesitating.
Beatriz Costa
Use it every day
Honestly didn't expect to like it this much. No-code evaluation workflows is exactly what I needed, and no coding required to run evaluations. but I reach for it almost every day now and it just clicks.
Perguntas e respostas
Ainda sem perguntas — sê o primeiro a perguntar.
Faz uma pergunta
Alternativas a AI Agents Platform


TheAgenticAI
AI Agents Platform
Platform for building and running reliable agentic AI workflows
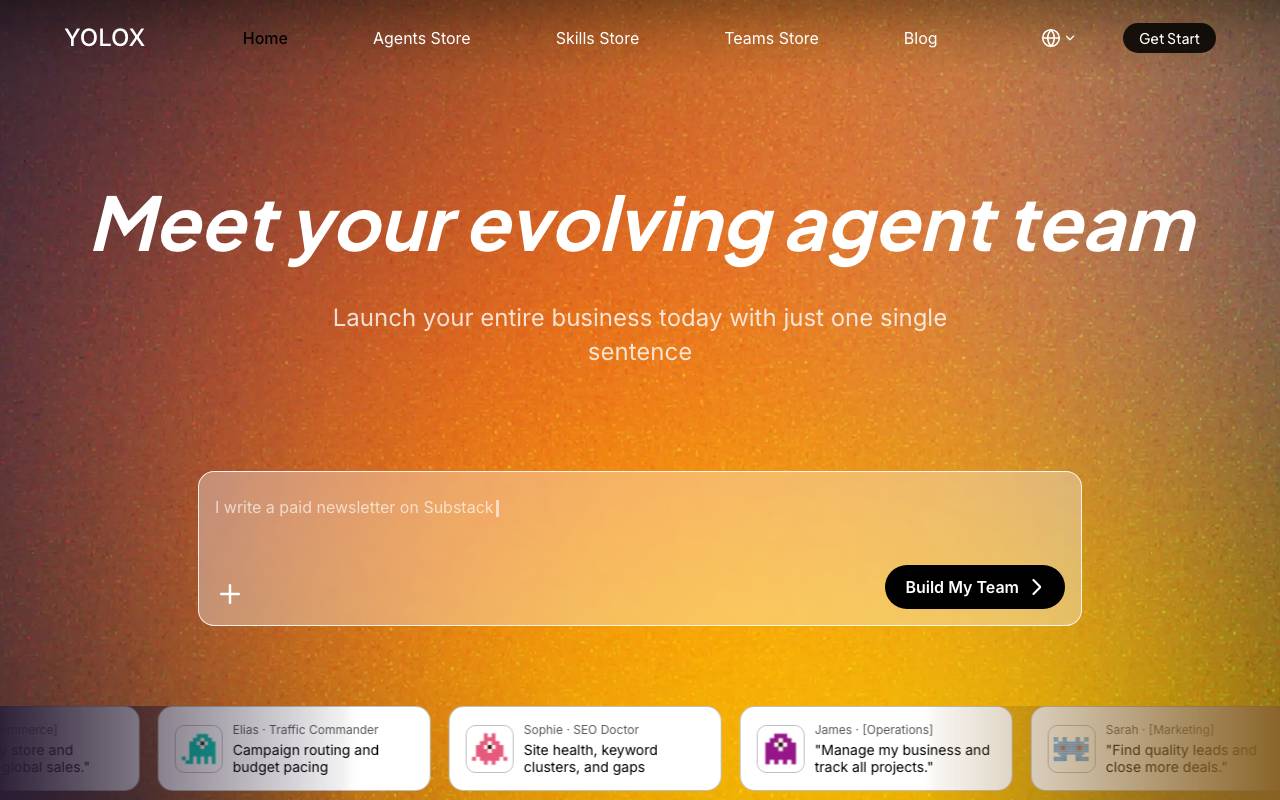

YOLOX
AI Agents Platform
Build and run a custom team of domain-specific AI agents that collaborate on your workflows.
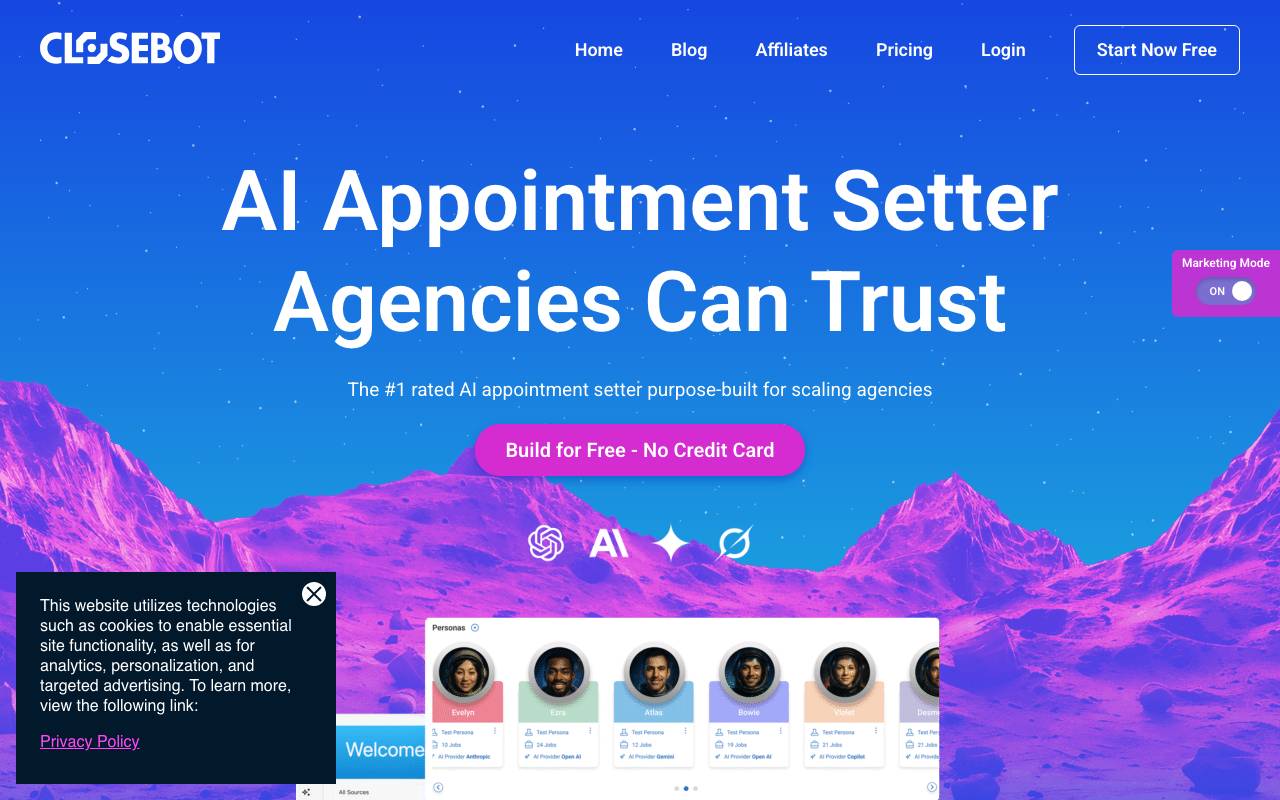
CloseBot
AI Agents Platform
AI sales chatbot that qualifies leads and books meetings automatically across SMS, web, and social channels.
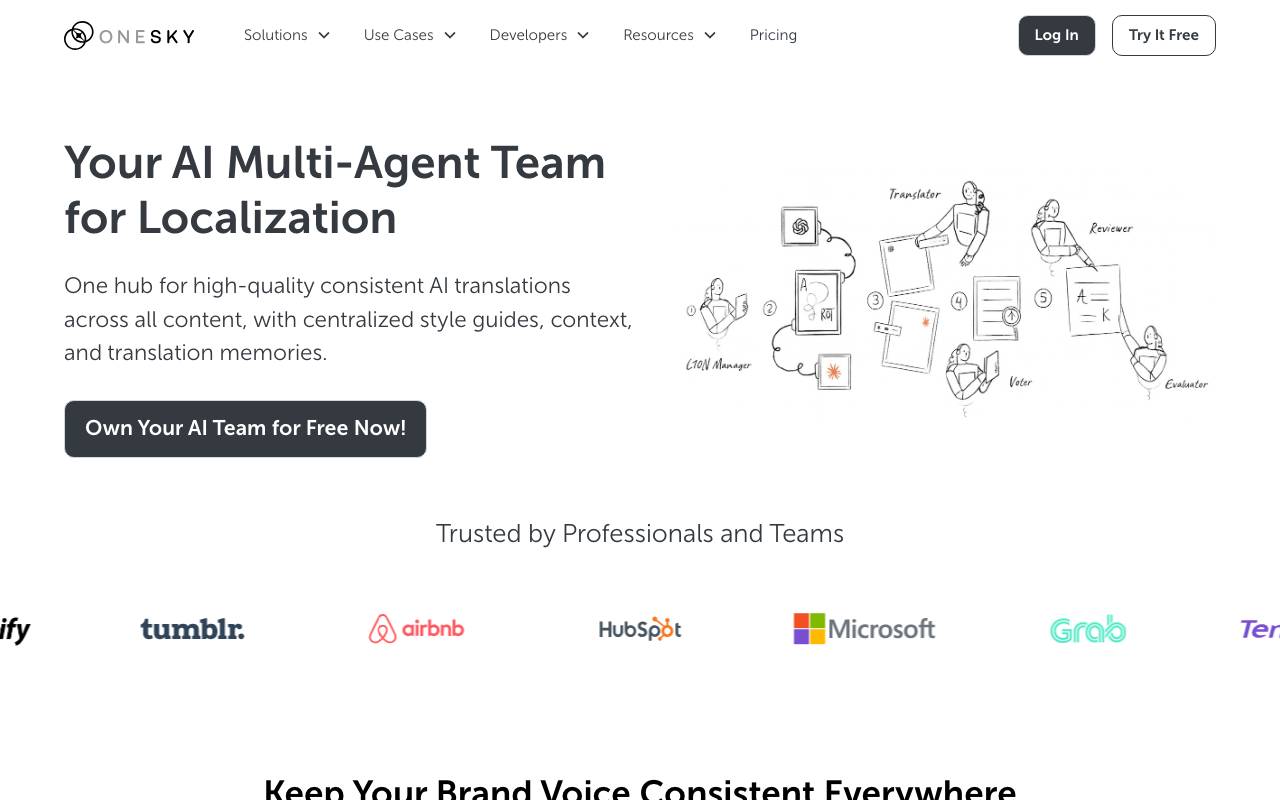

OneSky
AI Agents Platform
AI-powered localization platform for translating apps, games, and websites into global markets.
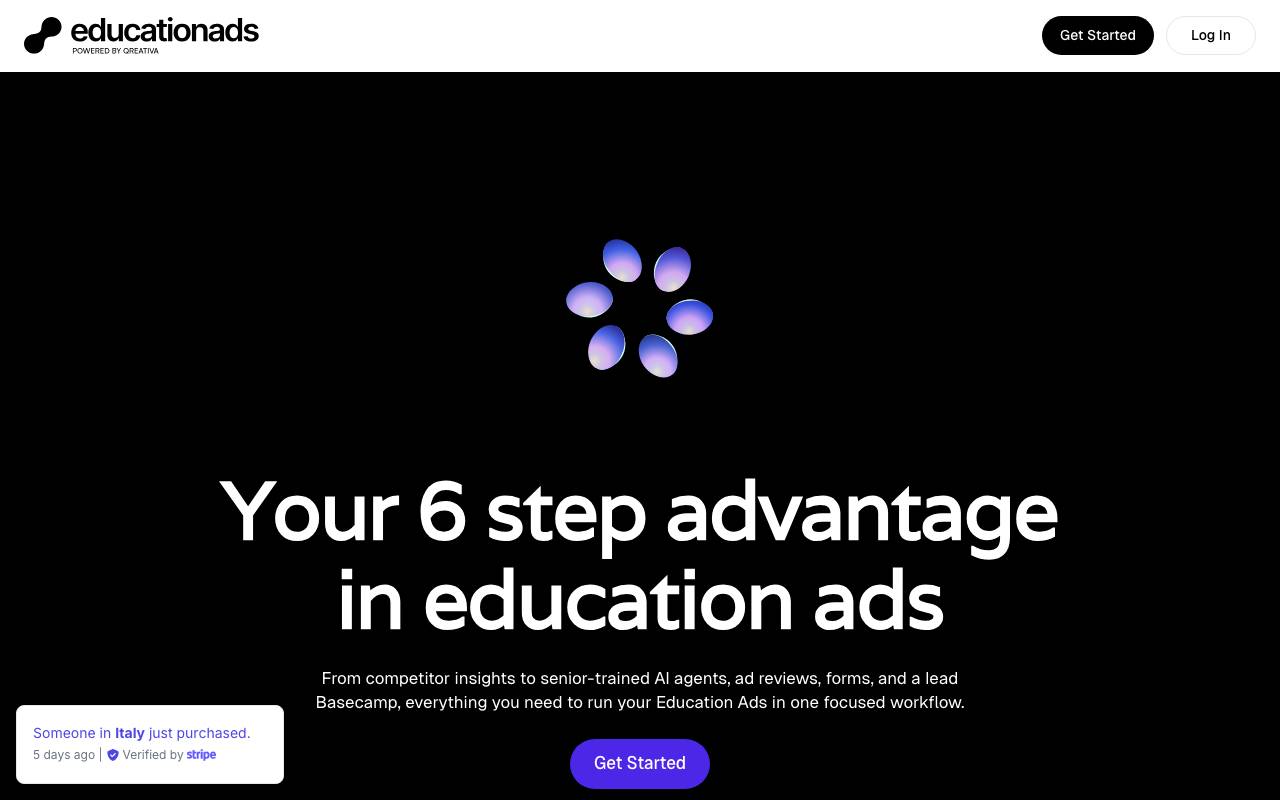
EducationAds AI
AI Agents Platform
AI ad copy and strategy assistant built specifically for schools and education programs.


OpenPipe AI
AI Agents Platform
Managed fine-tuning platform for building task-specific, cost-efficient LLMs
OpenAGI
AI Agents Platform
Framework for building autonomous AI agents that learn, plan, and act independently.
Tidio Copilot
AI Agents Platform
AI-powered assistant that automates customer service conversations and resolves support tickets in real time.